# 查看MySQL默认字符编码 \s 在5.x系列,会出现Latin1或gbk编码 在8.x系列,统一为utf8mb4,它是utf8优化版本,支持存储表情 # 统一字符编码 5.x 统一编码操作 my-default.ini配置文件 步骤1: 拷贝一份my-default.ini配置文件,并修改名称为my.ini 步骤二:清空my.ini文件内的内容 步骤三:添加固定的配置信息 [mysqld] character-set-server=utf8 collation-server=utf8_general_ci [client] default-character-set=utf8 [mysql] default-character-set=utf8 步骤四: 保存并重启服务端就ok了 net stop mysql net start mysql
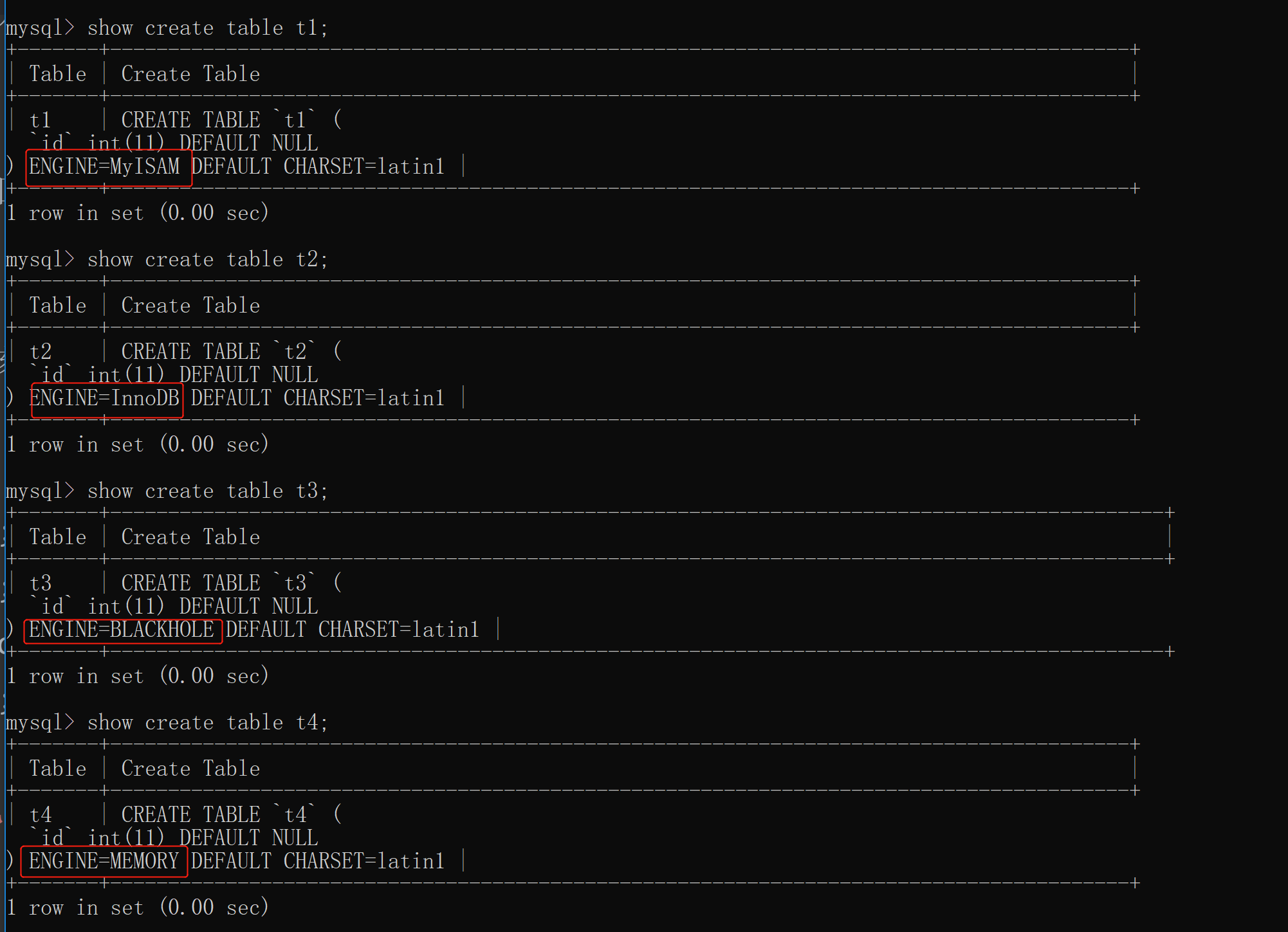
# 存储引擎含义 存储引擎可以理解为处理数据的不同方式 eg: a.txt文件 a会放密码箱里 b会转成pdf存储 c会做多个备份 d会制作封面美化 # 查看存储引擎 show engines; # 需要了解的引擎 # MyISAM 5.1之前版本MySQL默认的存储引擎 特点为:存取数据的速度快, 但是功能较少,安全性比较低 # InnoDB 5.1之后版本MySQL默认的存储引擎 特点: 功能较多,安全性较高,存取速度没有MyISAM快 # BlackHole 任何写到这个里面的数据都会消失(类似于垃圾回收处理站) # Memory 以内存作为数据存取地,速度快,但是一断电数据立刻丢失 # 自定义存取引擎 create table 名称(id int)engine=myisam; create table 名称(id int)engine=innodb; create table 名称(id int)engine=blackhole; create table 名称(id int)engine=memory;
create table 表名( 字段名1 字段类型(数字) 约束条件, 字段名2 字段类型(数字) 约束条件, 字段名3 字段类型(数字) 约束条件 ); 1、字段名和字段类型 是必须的, 2、数值和约束条件是可选的 3、约束条件可以写多个,直接空格隔开就可以 字段名1 字段类型(数字) 约束条件1 约束条件2 约束条件3, 4、最后一行字段结尾不能加逗号 eg: create table 表名( 字段名1 字段类型(数字) 约束条件, 字段名2 字段类型(数字) 约束条件, ) # 这样就是错的昂,错的
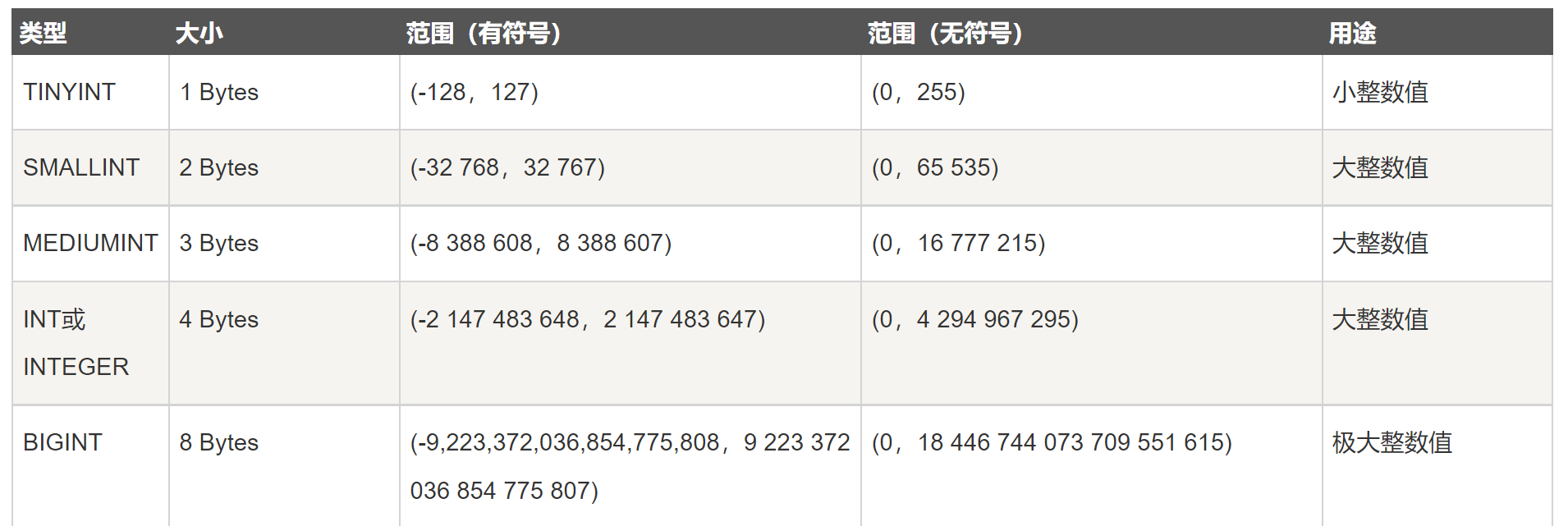
# 整型 tinyint 1bytes smallint 2bytes int 4bytes bigint 8bytes 上面整型的区别主要就是从上往下能够存储的数字范围越来越大 # 注意事项 1、需要考虑正负数的问题, 如果需要存储负数则需要占一个比特位 2、手机号如果使用整型存储, 需要使用bigint才可以 工作小技巧: 有时候看似需要使用数字类型存储的数据其实可能使用的是字符串、 应为字符串可以解决不同语言对数字不精确的缺陷 create table t5(id tinyint); insert into t5 values(-129),(256) # 当5.6版本不会报错,会自动处理成最大范围 想要修改的话 # 修改严格模式 步骤一: set global sql_mdoe = 'STRICT_TRANS_TABLES'; 步骤二:退出'客户端',重新登录就可以了 # ERROR 1264 (22003): Out of range value for column 'id' at row 1 # 在5.7及以上版本 就会直接报错(更加合理) 验证发现所有的整型都默认带有正负号,如果想要不带正负号————增加约束条件'unsigned不加正负号' create table t6(id tinyint unsigned)
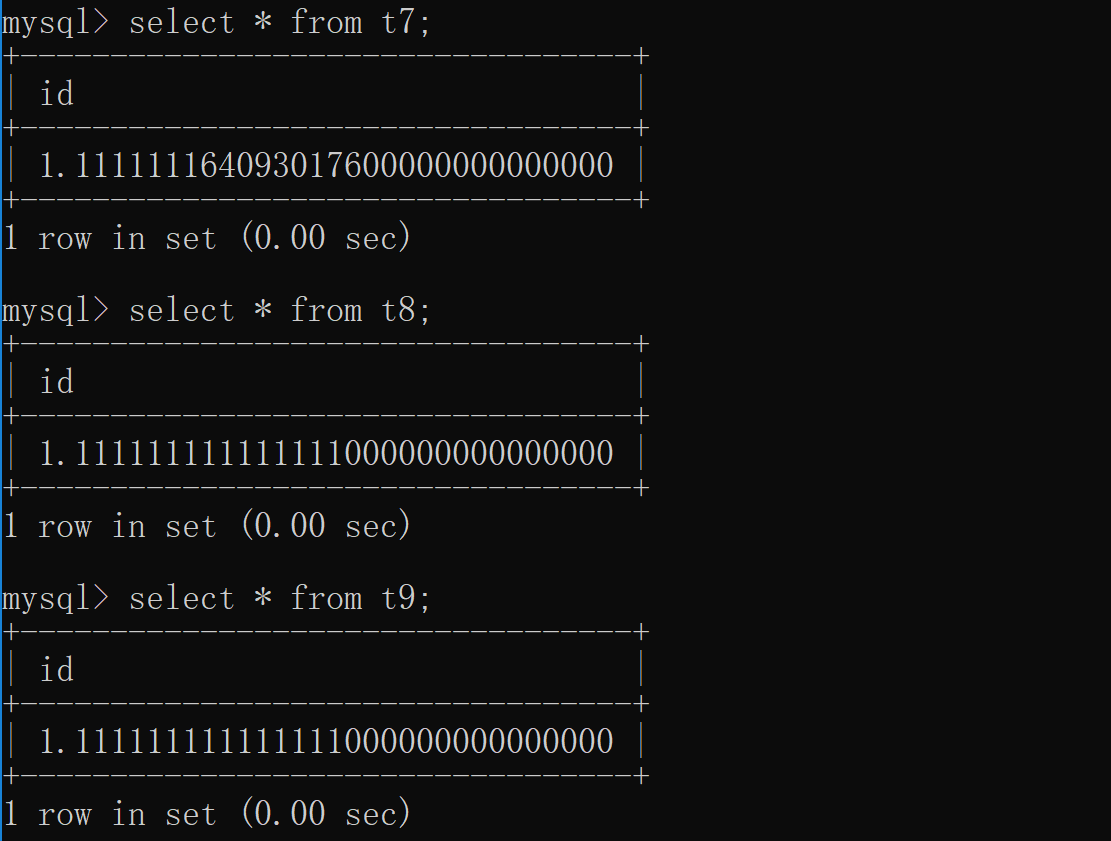
# 浮点型 float(255,30) double decimal 上述浮点型从上往下精确度越来越高 float(m, d) 4字节,单精度浮点型,m总个数,d小数位 float(255,30) 总共255位 小数位占30位 double(m, d) 8字节,双精度浮点型,m总个数,d小数位 double(255,30) 总共255位 小数位占30位 decimal(m, d) decimal是存储为字符串的浮点数 decimal(65,30) 总共65位 小数位占30位 # 实操 create table t7(id float(255,30)); create table t8(id double(255,30)); create table t9(id decimal(65,30)); insert into t7 values(1.111111111111111); insert into t8 values(1.111111111111111); insert into t9 values(1.111111111111111); decimal > double > float 使用范围: 正常业务精确度只要小数点三四位的样子的时候,使用float就可以 如果是科研业务,精确度要求极高,那么就使用decimal
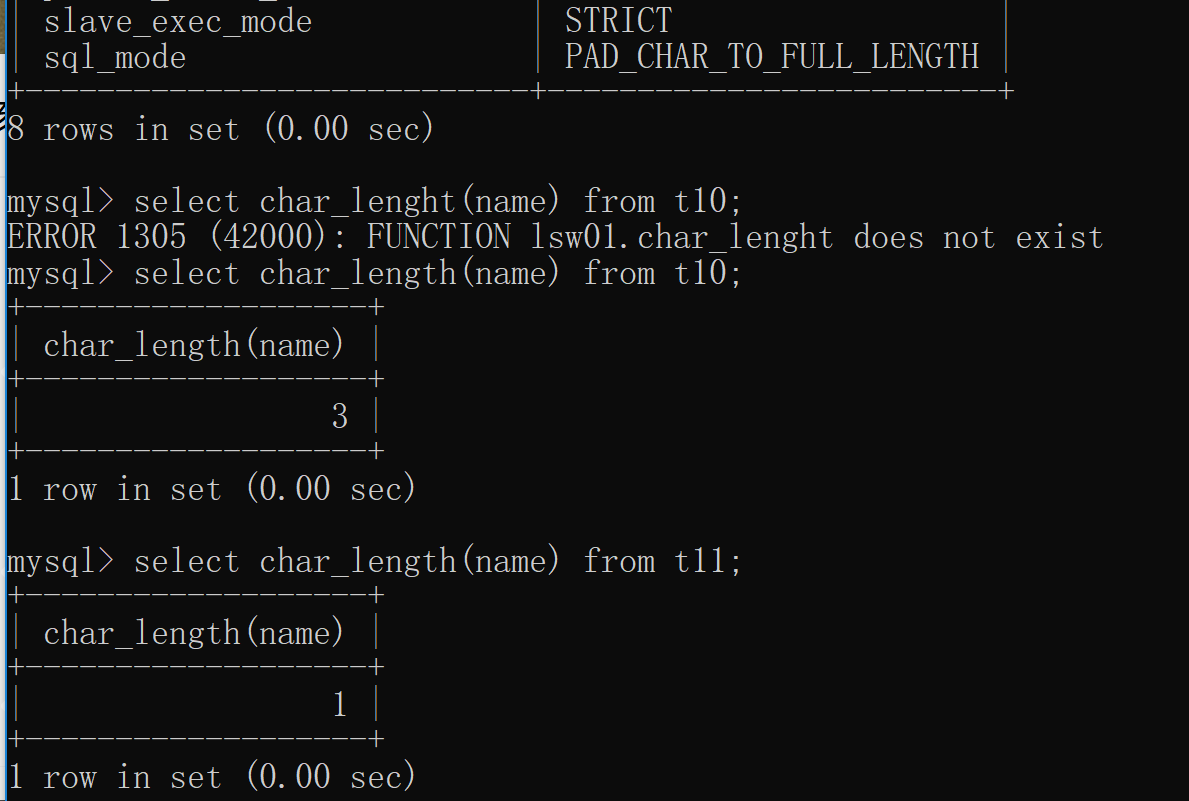
# 字符类型 char varchar 这两个的区别就在于一个是定长一个是变长 eg: char(3) 定长 —— 最大只能存储四个字符,超出则报错,不够则空格填充至四个 varchar(3) 变长 —— 最大只能存储四个字符,超出则报错,不够则有几个存几个 # 验证定长和变长的特性 create table t10(name char(3)); create table t11(name varchar(3)); insert into t10 values('owen'); # ERROR 1406 (22001): Data too long for column 'name' at row 1 insert into t11 values('owne'); # ERROR 1406 (22001): Data too long for column 'name' at row 1 insert into t10 values('a'); # Query OK, 1 row affected (0.01 sec) insert into t11 values('a'); # Query OK, 1 row affected (0.01 sec) # 在5.6版本并且没有修改严格模式时,则会自动截取四个字符 # 临时修改 步骤1: set global sql_mode = 'STRICT_TRANS_TABLES'; 步骤2: 退出'客户端' 重新登录 # 永久修改 修改my.ini 配置文件 sql_mode = 'STRICT_TRANS_TABLES,ONLY_FULL_GROUP_BY' 重启服务端之后永久生效 获取字段数据的长度 char_length() 这个方法无法直接获取到定长的真实长度,因为MySQL在存数据的时候会自动填充空格在取数据的时候又会自动移除空格 想要让MySQL在取数据的时候不自动移除空格 set session sql_mode = 'pad_char_to_full_length'; # 工作使用 char 整存争取 速度快(就是会造成一定存储空间的浪费) 可能会造成黏包形式的现象 ''' owenkevinmary tom ''' varchar 节省存储空间 存取数据的速度没有char快 ''' varchar在存数据的时候会生成一个1bytes的报头 记录数据长度 varchar在取数据的时候先会读取1bytes的报头 从中获取真实数据长度 1bytes+owen1bytes+kevin1bytes+mary 1bytes+tom ''' 两者都有使用场景 针对统一中国人的姓名,应该采取 ———— varchar 规模较小,数据量相对固定的字典 ———— char 很多时候字段类型的选取和命名都会在邮件中标明
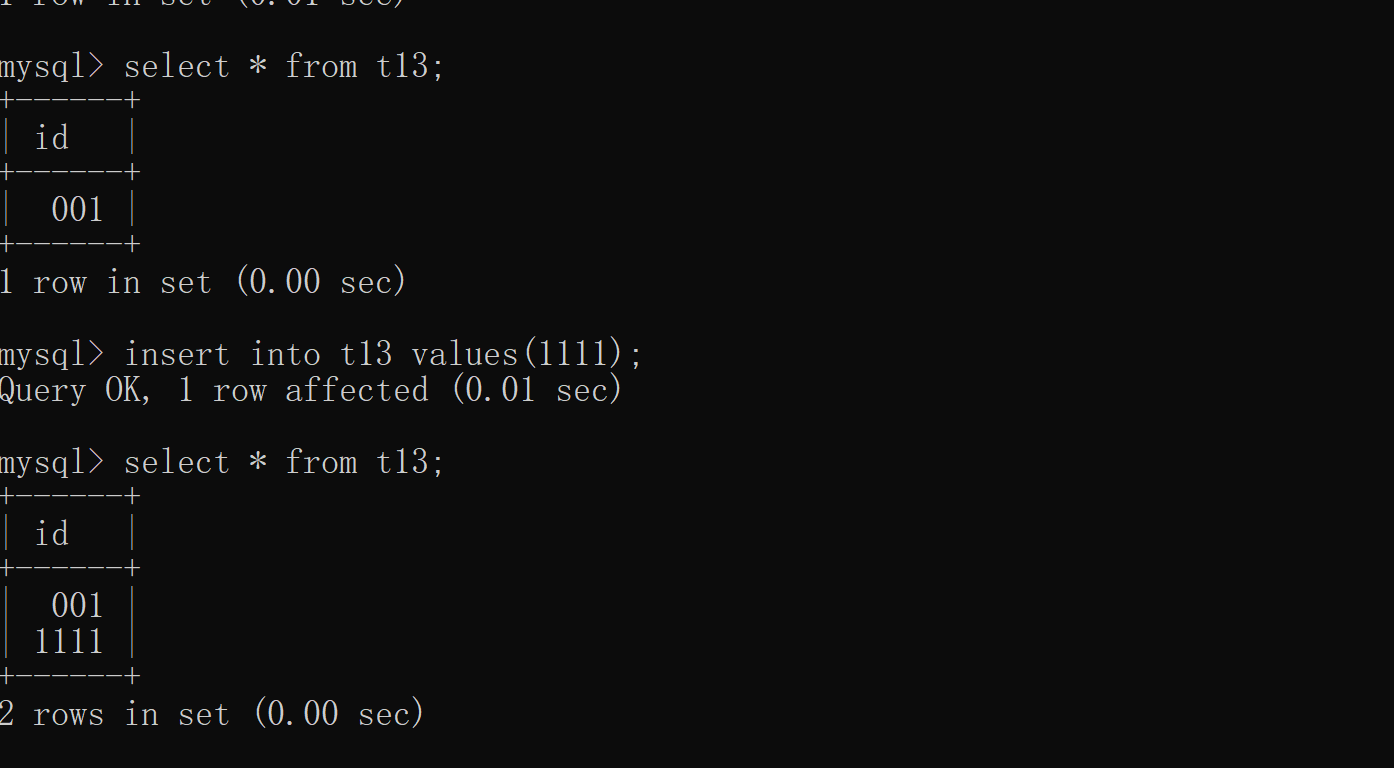
字段类型括号内的数字大部分情况下是用来限制存储的长度 但在整型中并不是用来限制长度的,而是用来控制展示长度的 create table t12(id int(3)); insert into t12 values(1111); create table t13(id int(3) zerofill); # 位数不够用0填充 insert into t13 values(1); insert into t13 values(1111); # 有几位展示几位 结论: 涉及到整型字段 都无需自己定义长度 直接使用自带的 针对其他类型的字段,则需要自己添加数字
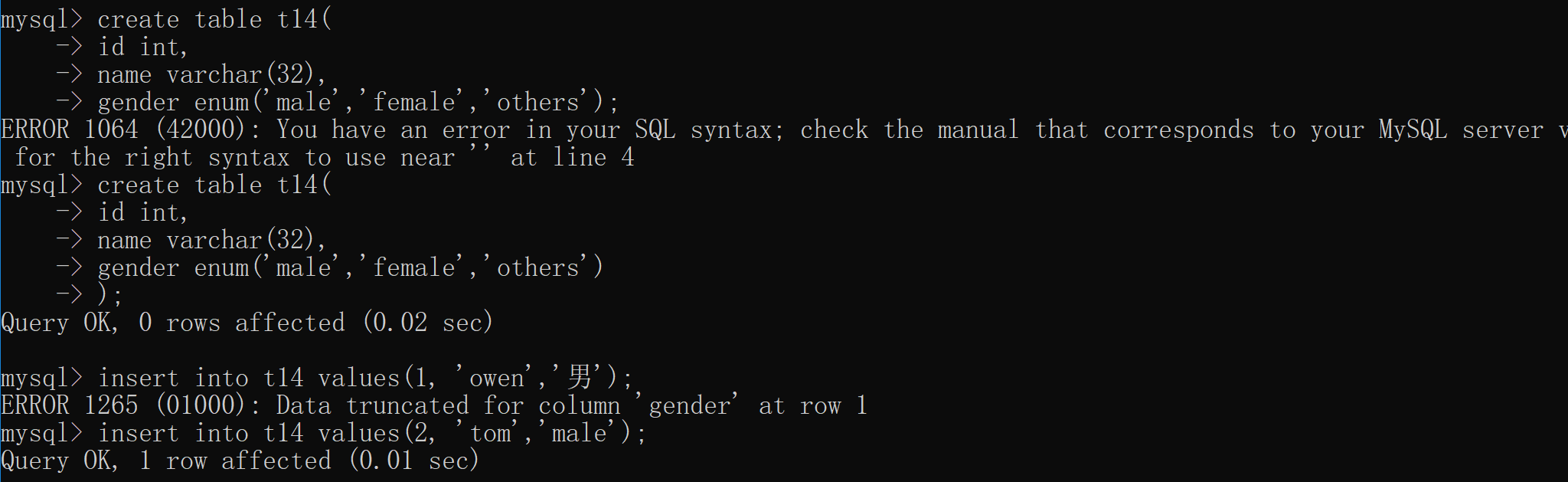
# 枚举 多选一的模式 create table t15( id int, name varchar(32), gender enum('male','female','others') ); insert into t14 values(1, 'owen','男'); # 报错 insert into t14 values(2, 'tom','male'); # 不报错 ''' 插入数据的时候,正对gender只能填写提前定义好的数值 '''
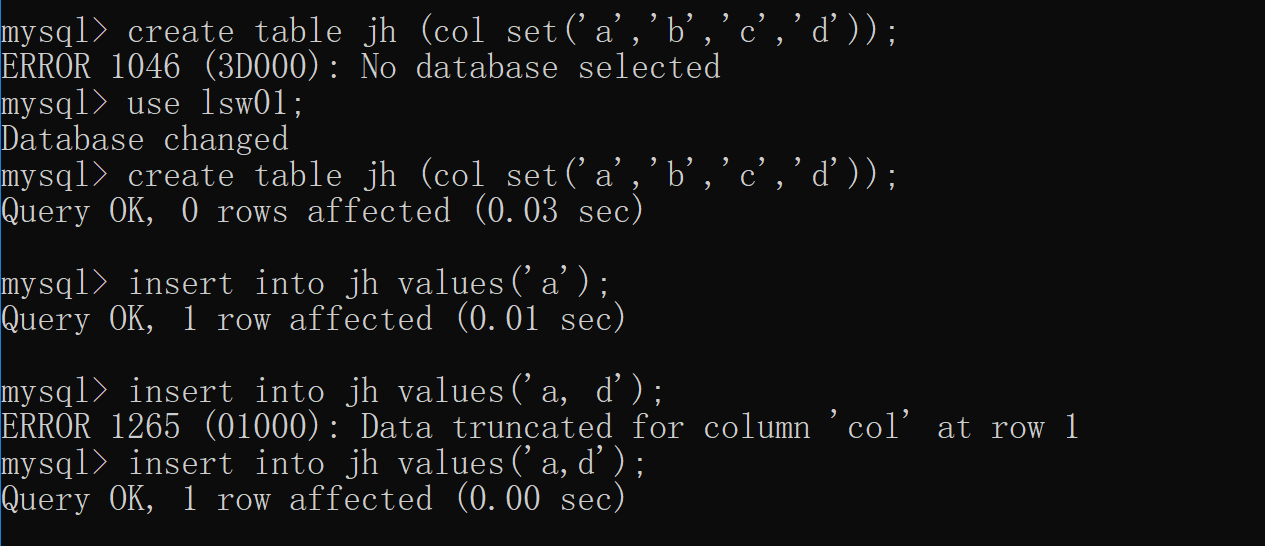
# 集合 多选多(也可以多选一) create table jh (col set('a','b','c','d')); insert into jh values('a'); insert into jh values('a, d');
date 年月日 datatime 年月日时分秒 time 时分秒 year 年 create table sj( reg_time datetime, birth date, study_time time, join_time year ); insert into sj values('2001-12-12','1988-01-21','13:14:11','2001');

# 字段类型与约束条件的关系 约束条件时基于字段类型之上的额外限制 eg: id int unsigned id int 字段类型int规定了id 字段只能存整数 约束条件unsigned指在整数的基础上还必须为正数 # 无需正负号 unsigned # 零填充 zerofill # 非空 not null
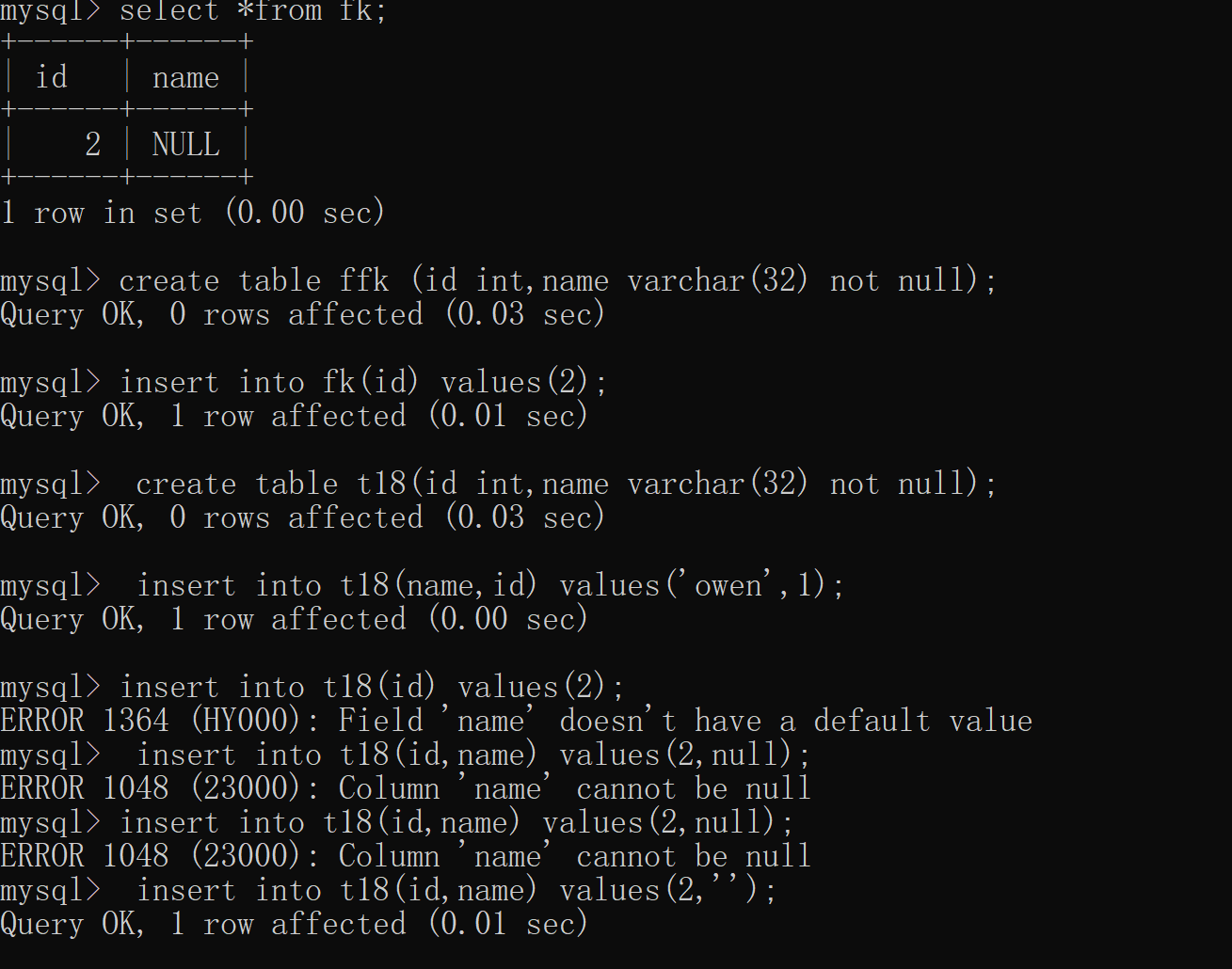
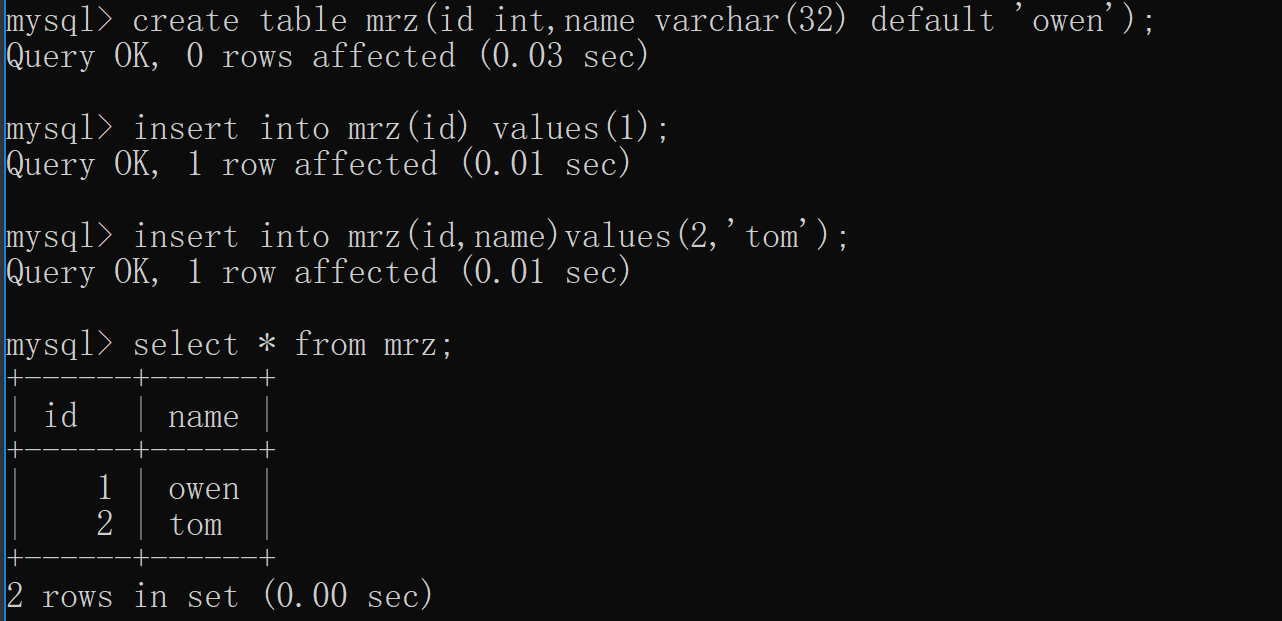
# 默认值 default create table mrz(id int,name varchar(32) default 'owen'); insert into mrz(id) values(1); insert into mrz(id,name)values(2,'tom'); # 传值就用自己的,不传值就为默认值
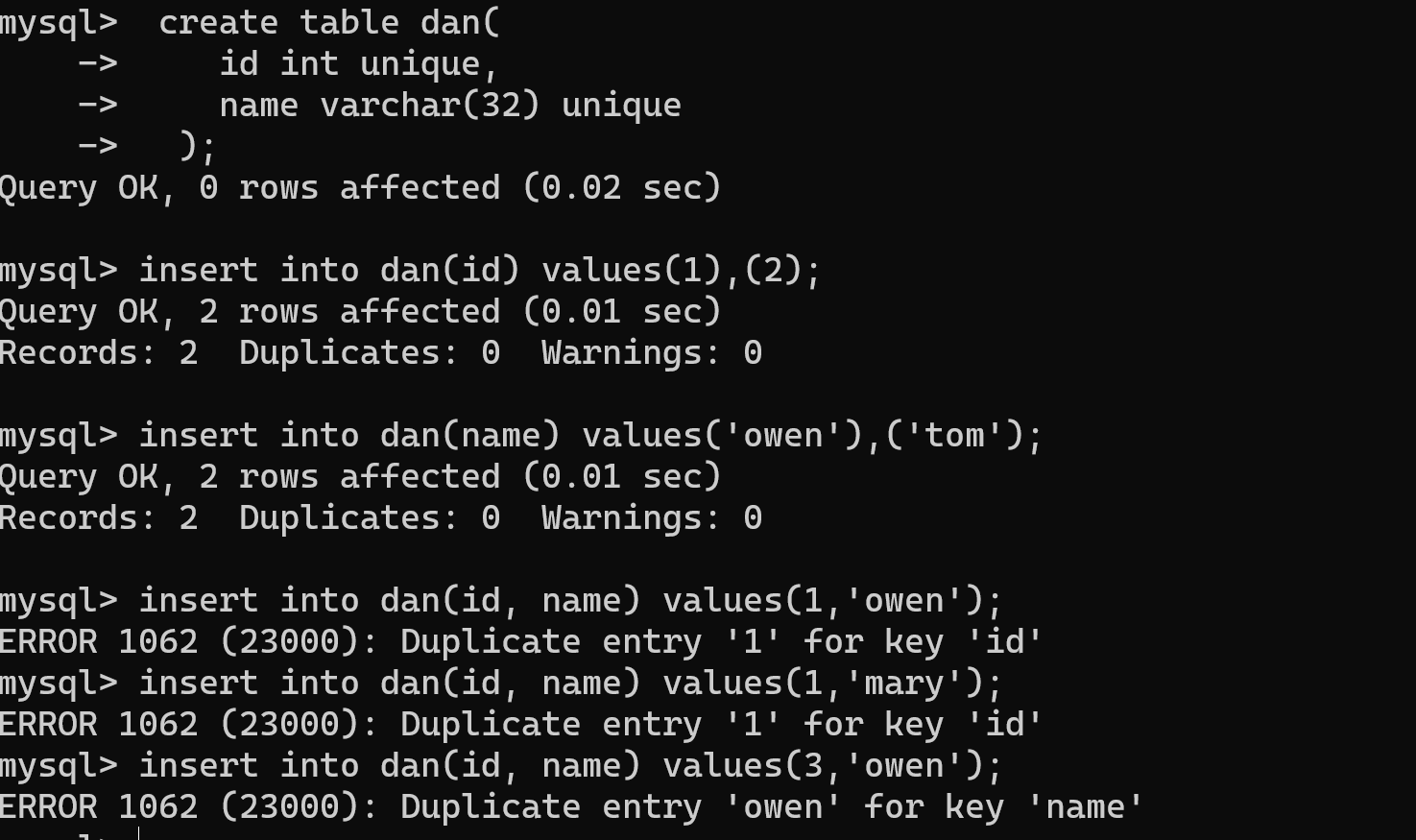
# 唯一值 unique ''' 单列唯一: 某个字段下对应的数据不能重复 ''' create table dan( id int unique, name varchar(32) unique );
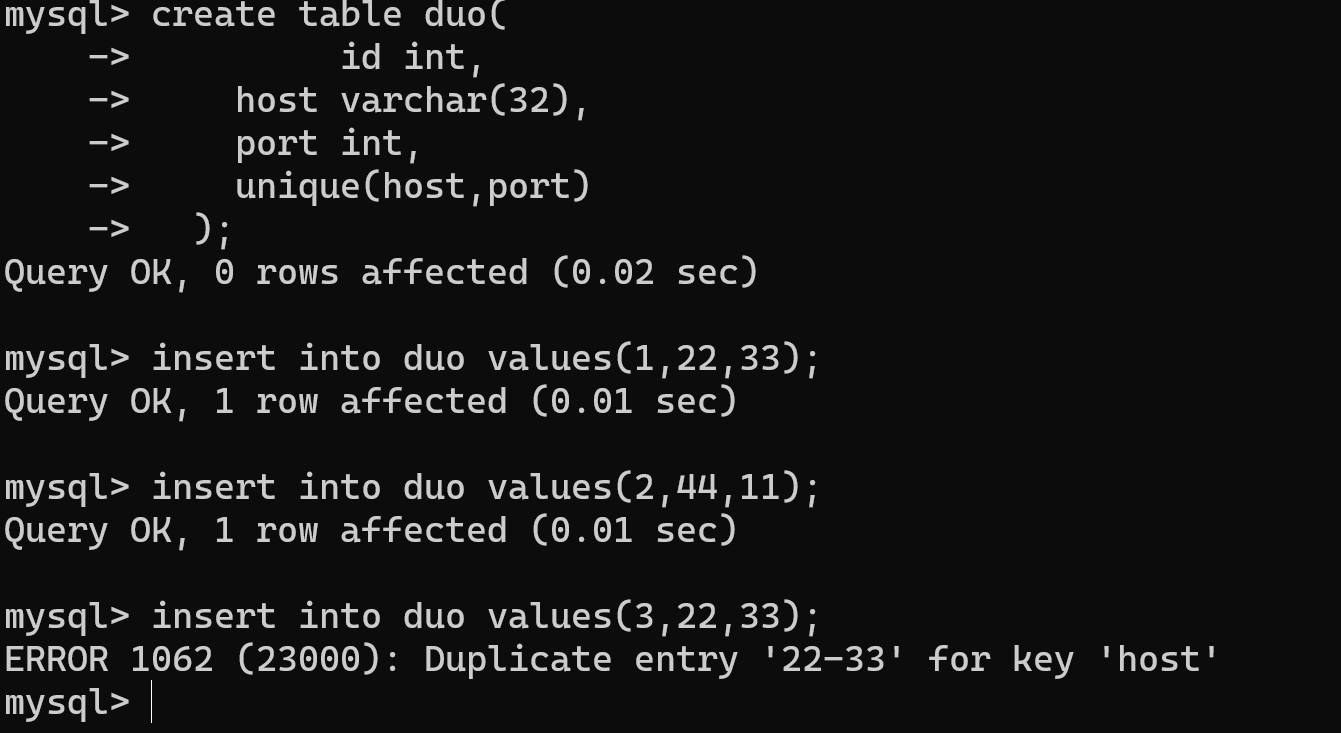
''' 多列唯一: 多个字段下对应的数据组合到一起的结果不能重复,必须为唯一 ''' create table duo( id int, host varchar(32), port int, unique(host,port) );
# 主键 primary key 1.单从约束层面上而言 相当于not null + unique(非空且唯一) create table zj(id int primary key); mysql> insert into zj values(); ERROR 1364 (HY000): Field 'id' doesn't have a default value mysql> insert into zj values(1); Query OK, 1 row affected (0.00 sec) mysql> insert into zj values(1); ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY' 2.是InnoDB存储引擎规定的一张表有且必须要有一个主键 用于构建表 主键可以加快数据的查询速度(类似于书的目录) 如果创建表创建的时候没有设置主键也没有其他的键 那么InnoDB会采用一个隐藏的字段作为表的主键(隐藏就意味着而无法使用 即无法加快数据查询) 如果没有主键但是有非空且唯一的字段 那么会自动升级成主键(从上往下的第一个) create table t23( tid int, pid int not null unique, cid int not null unique ); # 创建表应该有一个序号字段(id\pid\cid)并且应该将该字段设置成主键 create table zhuj( id int primary key, name varchar(32) );
# 自增 auto_increment 专门配合主键一起使用,用户以后在添加数据的时候就不需要自己记忆主键值 create table zz( id int primary key auto_increment, name varchar(32) ); 一般都会有一个主键字段的编写 id int primary key auto_increment